Product: WebViewer
Product Version: 8.0.1
Please give a brief summary of your issue:
(Think of this as an email subject)
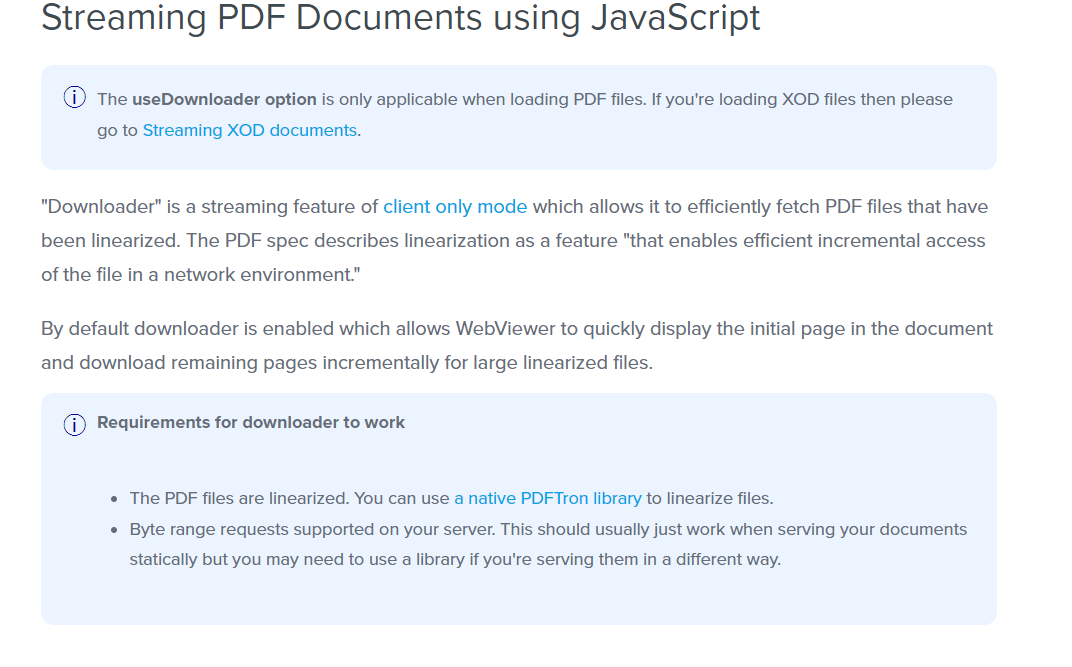
Pdf pages are not loading incrementally, instead whole pdf is getting loaded and that is taking a lot of time
Please describe your issue and provide steps to reproduce it:
(The more descriptive your answer, the faster we are able to help you)
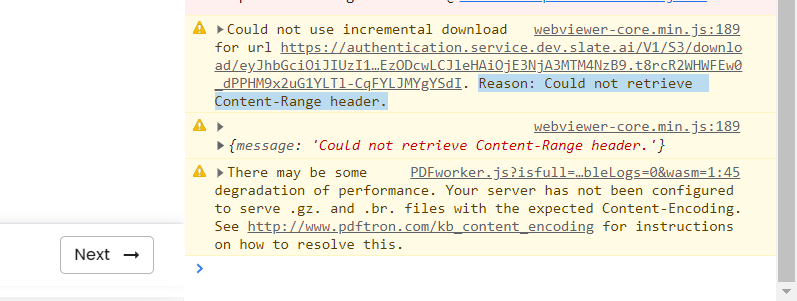
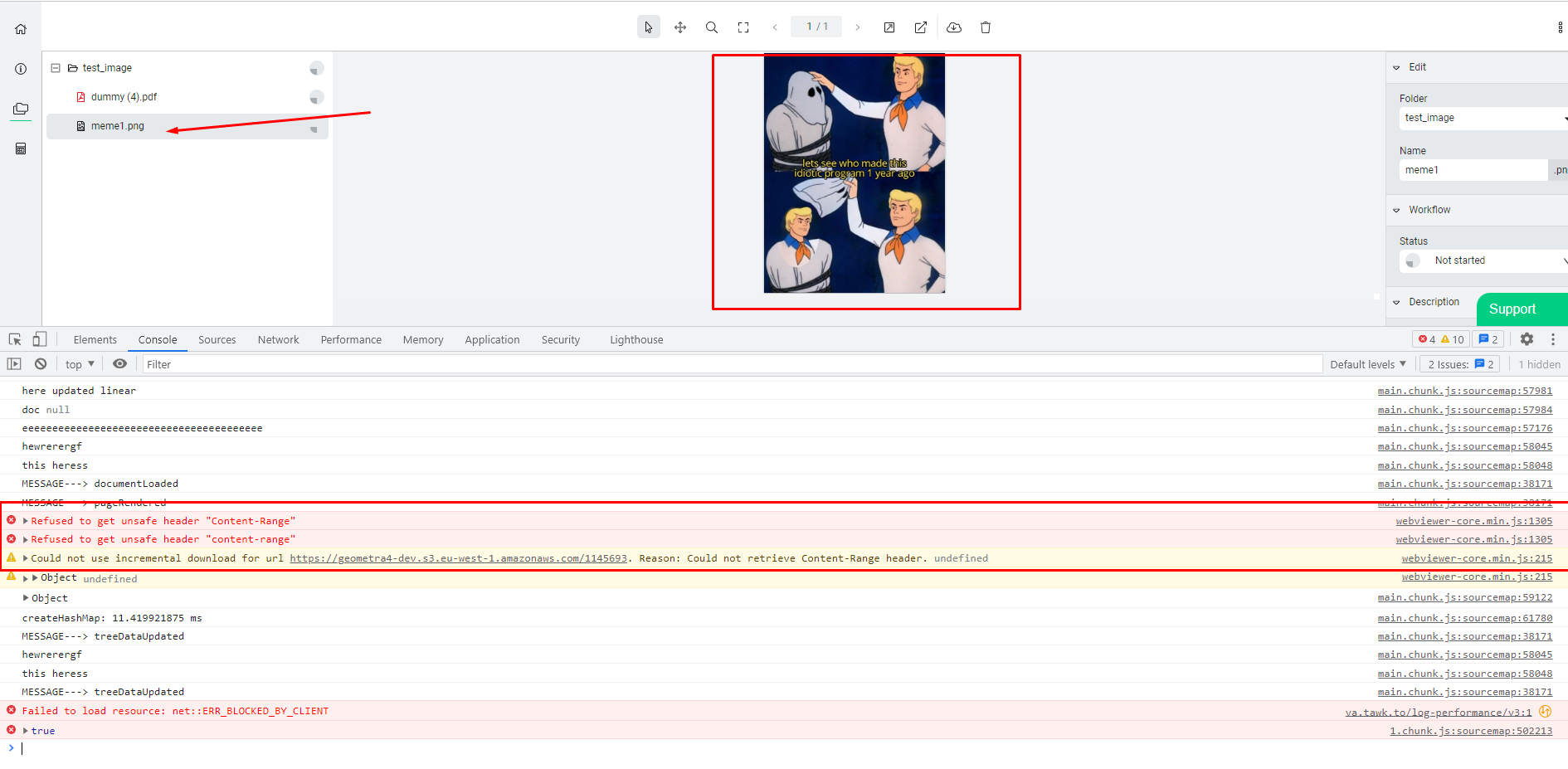
Whenever I am opening pdf’s in client side, I am getting this message in console that says Could not use incremental download , Reason: Could not retrieve Content-Range header.
Even after setting the Access-Control-Expose-Headers: Content-Range in server side the issue still persist.
We are using amazon aws s3 for storing the pdf
Please provide a link to a minimal sample where the issue is reproducible:
This is how I am setting CORS in node app
private config(): void {
const options: cors.CorsOptions = {
allowedHeaders: [
'Origin',
'X-Requested-With',
'Content-Type',
'Accept',
'X-Access-Token',
'Authorization',
],
exposedHeaders:[
'Content-Range'
],
credentials: true,
methods: 'GET,HEAD,OPTIONS,PUT,PATCH,POST,DELETE',
origin: '*',
preflightContinue: false,
};
this.app.use(cors(options));
this.app.options('*', cors(options));
this.app.use(bodyParser.json({ limit: '50mb', type: 'application/json' }));
this.app.use(bodyParser.urlencoded({ limit: '50mb', extended: true, parameterLimit: 50000 }));
this.app.use(Morgan(':method :url :status :res[content-length] - :response-time ms'));
}`Preformatted text`
This is the message i am getting and that is stopping me from testing my linearized pdf for fast loading of pages: