I am trying to convert an HTML string to PDF using HTML2PDF and make it accessible using the tag information that comes with the PDFDoc.
HTML string conversion looks like this;
PDFDoc doc = new PDFDoc();
string html = “<html><body><h1>Heading</h1><p>Paragraph.</p></body></html>”
converter.InsertFromHtmlString(html);
converter.Convert(doc);
After the conversion, when I tried to process the elements in the PDFDoc and tried to see what the MCTag returns for each text element(e_text); (in this case Heading and Paragraph)
var tag = element.GetMCTag();
tag.GetName() returns “P” as the element tag for Heading which I expected to have “h1” instead. For “Paragraph” it gave the correct MCTag which is “P”.
Am I missing something during the conversion? or is there a way to get the correct tag information when it comes to headings (H1-H6) in HTML or any way of getting the heading info after the conversion?
Hi Ryan,
Yes, we are trying to create a logical structure out of an untagged pdf (which is converted from HTML to PDF using HTML2PDF). Because the requirement is to make a PDF/UA compliant PDF. So in the logical structure tree, the headings should be identified as headings and tagged accordingly. So the assistive technology can identify what’s heading and what’s a paragraph.
I have added this feature request to the product backlog, but at this time it is not on our schedule.
If instead your input was a DOCX file, then the PDF output with our SDK is fully tagged with the H1-H6 tags. Is switching from HTML to DOCX an option for you?
I am happy to report that starting with our next release, PDFNet 9.4, the HTML2PDF module output will be a Tagged PDF, and the H1-H6 entries will be preserved and present in the PDF output.
To get notified for the next official SDK release you can join our Discourse Announcements channel.
For platform specific notifications, such as Nuget, NPM, CocoaPods, please see the respective PDFTron product documentation page.
While not as fully tested as our official releases, this should be fine for production usage, as the only change from the official release is the flag to generate a Tagged PDF.
Hi,
Thank you for the response.
I was checking the dll, but the output was the same - untagged PDF. Do I have to set some properties or is it only will be available in the released version?
I am using this on the attached file here; html.txt (10.4 KB)
HTML2PDF converter = new HTML2PDF();
converter.InsertFromHtmlString(contentString);
converter.Convert(doc)
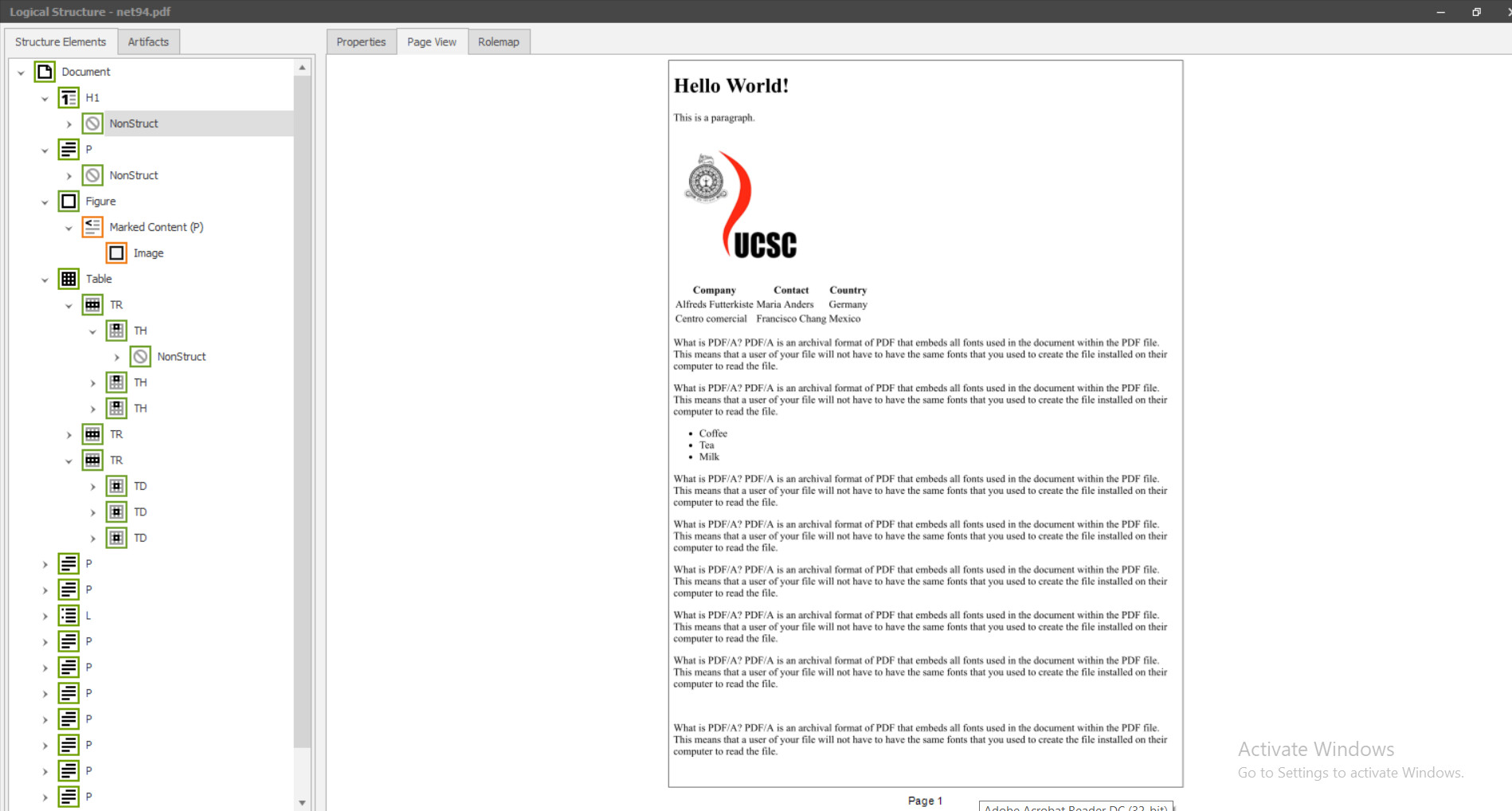
I was able to test it, I could see that the logical structure is being created now with the new version of PDFTron . But it seems it doesn’t do the mapping properly. Was it intentional or is it because the DLL is still under development?
But anyways if the content is coming as marked content I’ll be able to map the pdf elements with the logical structure tree using the PDFTron Systems Inc. | Documentation documentation. I’ll let you know if that’s doable in this state
Thank you for the quick update