Hello ,
a quick question , we are trying to extract some text zones from pdf in particular Layer , is there a way to to achieve that ?
(thank u in advance)
Hello,
Yes, you can extract text from a given layer, although it may be a little tricky, as the following post points out, you must copy the desired Optional Content Group (OCG) to a temporary page:
Can you clarify what you mean by “extract some text zones”?
Do you mean extract text from some areas, or get the areas of the extracted text?
May I ask what you are going to do with this information (perhaps I can make suggestions).
Joe
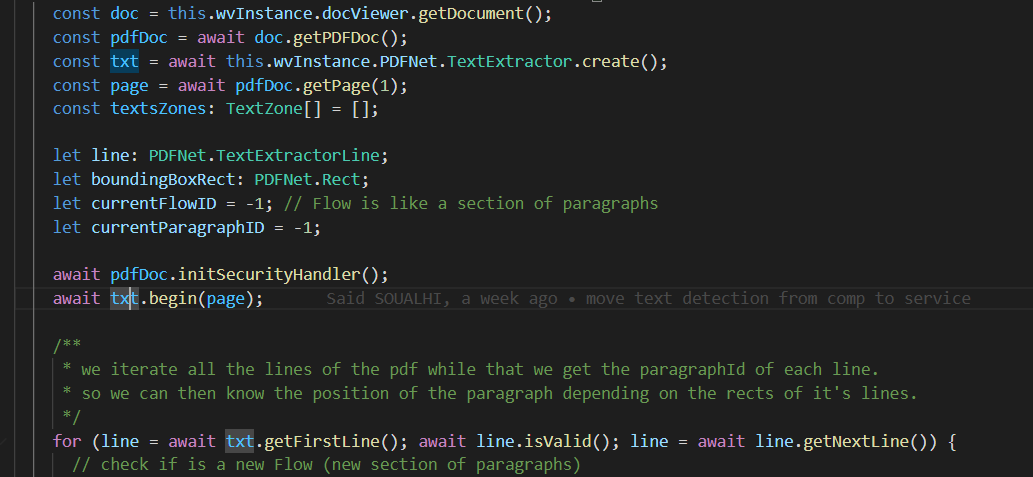
we are using this code https://www.pdftron.com/documentation/web/guides/extraction/text-extract/ to extract the borders for all paragraphs drawn beforehand.
this is my code :
const doc = this.wvInstance.docViewer.getDocument();
const pdfDoc = await doc.getPDFDoc();
const txt = await this.wvInstance.PDFNet.TextExtractor.create();
const page = await pdfDoc.getPage(1);
is there a way to specify what layer we want to use before doc.getPDFDoc();
i tried this :
doc.setLayersArray([]);//empty array of layers
this.wvInstance.docViewer.refreshAll();
but it didn’t work
Hello,
You can give the text extractor a context, indicating the given OCG layer to use for text extraction.
Below is an example snippet (written in C#) that extracts text from the third layer
(please note the comment “// index of layer”).
For the most part, the APIs are 1:1, so it should be easy to translate.
It is important to note the call to SetNonOCDrawing(false) to indicate that any non OCG content (non layer content) is not to be extracted. This will filter out any text that exists directly on the page.
using pdftron.PDF.OCG;
...
doc.InitSecurityHandler();
Page page = doc.GetPage(1);
...
Obj ocgs = doc.GetOCGs();
Group ocg = new Group(ocgs.GetAt(2)); // index of layer
Config init_cfg = doc.GetOCGConfig();
Context ctx = new Context(init_cfg);
ctx.SetNonOCDrawing(false); // turn off non-optional content
ctx.ResetStates(false); // turn off all optional
ctx.SetState(ocg, true); // given ocg of target layer
using (TextExtractor txt = new TextExtractor())
{
txt.SetOCGContext(ctx);
txt.Begin(page); // Read the page.
TextExtractor.Word word;
for (TextExtractor.Line line = txt.GetFirstLine(); line.IsValid(); line = line.GetNextLine())
{
for (word = line.GetFirstWord(); word.IsValid(); word = word.GetNextWord())
{
Console.WriteLine(word.GetString());
}
}
Additionally, you may want to look at the following samples to help in translating the above C# code to JavaScript.
PDFLayers Example
C#
JavaScript
TextExtract Example
C#
JavaScript
If the above does not help, then please elaborate and provide an example file we can review.
Joe
RONDO_ESKO_EYEC (2).PDF (882.8 KB)
hello @JoeHecht , i tried this approach i set the states to false for all layers just for test 
await Context.resetStates(false);
await Context.setNonOCDrawing(false),
but when iterating the document i get the same result , it detects all the text Paragraphs, 
you can find the pdf file im using attached the layer that has text Paragraphs is named:“Graphic”
thank u so much 
Thank you for the example file.
I see that has layers, and in particular all the text is on layer “Graphics”.
Could you please provide all the related code you used to turn off layers and non-optional content, and to extract the text, so we can do a code review?
this is my code :
const textsZones: TextZone[] = [];
const doc = this.wvInstance.docViewer.getDocument();
const pdfDoc = await doc.getPDFDoc();
const txt = await this.wvInstance.PDFNet.TextExtractor.create();
const page = await pdfDoc.getPage(1);
const initCfg = await pdfDoc.getOCGConfig();
const pdfTronContext = await this.wvInstance.PDFNet.OCGContext.createFromConfig(initCfg);
const ocgs = await pdfDoc.getOCGs();
const sz = await ocgs.size();
await pdfTronContext.resetStates(false);
await pdfTronContext.setNonOCDrawing(false); // turn off non-optional content
for (let i = 0; i < sz; ++i) {
const ocg = await this.wvInstance.PDFNet.OCG.createFromObj(await ocgs.getAt(i));
const stat = await pdfTronContext.getState(ocg);
console.log(stat);
const ocgObjectName = await ocg.getName();
//the layer that we want to extract the text from
if (‘Graphic’ === ocgObjectName) {
await pdfTronContext.setState(ocg, false);
}
}
let line: PDFNet.TextExtractorLine;
let boundingBoxRect: PDFNet.Rect;
let currentFlowID = -1; // Flow is like a section of paragraphs
let currentParagraphID = -1;
await pdfDoc.initSecurityHandler();
await txt.begin(page);
await txt.setOCGContext(pdfTronContext);
/**
* we iterate all the lines of the pdf while that we get the paragraphId of each line.
* so we can then know the position of the paragraph depending on the rects of it's lines.
*/
for (line = await txt.getFirstLine(); await line.isValid(); line = await line.getNextLine()) {
// check if is a new Flow (new section of paragraphs)
if ((await line.getFlowID()) !== currentFlowID) {
if (currentFlowID !== -1 && currentParagraphID !== -1) {
currentParagraphID = -1;
}
currentFlowID = await line.getFlowID();
}
// check if is a new paragraph
if ((await line.getParagraphID()) !== currentParagraphID) {
currentParagraphID = await line.getParagraphID();
const textZone = textsZones.find(t => t.paragraphId === currentParagraphID && t.flowId === currentFlowID);
if (!textZone) {
textsZones.push({
flowId: currentFlowID,
paragraphId: currentParagraphID,
rectsList: []
});
}
}
boundingBoxRect = await line.getBBox();
const textZone = textsZones.find(t => t.paragraphId === currentParagraphID && t.flowId === currentFlowID);
if (textZone) {
textZone.rectsList?.push({
x1: boundingBoxRect.x1,
y1: boundingBoxRect.y1,
x2: boundingBoxRect.x2,
y2: boundingBoxRect.y2
});
}
}
TextZone {
flowId: number;
paragraphId?: number;
rectsList?: Array;
}
AnnotationRects {
x1: number;
y1: number;
x2: number;
y2: number;
}
Change the the order of these lines:
From:
await txt.begin(page);
await txt.setOCGContext(pdfTronContext);
To:
await txt.setOCGContext(pdfTronContext);
await txt.begin(page);