Product: PDFTron SDK for Kotlin/Java Product Version: 11.0.0
Brief Summary:
Garbled characters when displaying Chinese PDF in Android SDK - suspected font embedding issue
Issue Description:
I am experiencing an issue with garbled characters when opening a specific Chinese PDF file using the PDFTron Android SDK. The text content, which should display Chinese characters, appears as random symbols or incorrect characters, making the document unreadable.
The issue occurs consistently with this particular Chinese PDF file
Other PDF files (including non-Chinese ones) render correctly in the SDK
I suspect this might be related to font embedding issues within the PDF
The font information from Adobe Acrobat shows the embedded fonts as shown in the screenshot
Troubleshooting Steps Taken:
Confirmed the same PDF displays correctly in Foxit PDF Reader on desktop
Tested with different PDF files in the Apryse SDK to verify the issue is specific to this Chinese file
Checked font embedding information in Adobe Acrobat
Questions:
Could you confirm if this is likely caused by incomplete or improper font embedding in this PDF?
Are there any recommended solutions or workarounds within the PDFTron SDK to handle such cases?
Are there any SDK-side configurations to better handle font rendering for such PDFs?
The problem persists despite these troubleshooting steps. I would appreciate it if you could investigate whether this is a known issue. Let me know if you need the PDF file in question for testing.
Hello, I’m AiRon, an automated tech support bot While you wait for one of our customer support representatives, I can help you with your question.
Garbled characters in PDF rendering, especially for Chinese or other non-Latin scripts, often arise from font embedding issues. When fonts aren’t properly embedded in the PDF, the viewer may not display the characters correctly if it doesn’t have access to the necessary fonts.
Some things you can try:
Check if the fonts are embedded in the PDF. If not, consider embedding them using a PDF editor or through a PDF processing library.
Ensure that the Android device has the necessary fonts installed. You can bundle fonts with your app to ensure they are available.
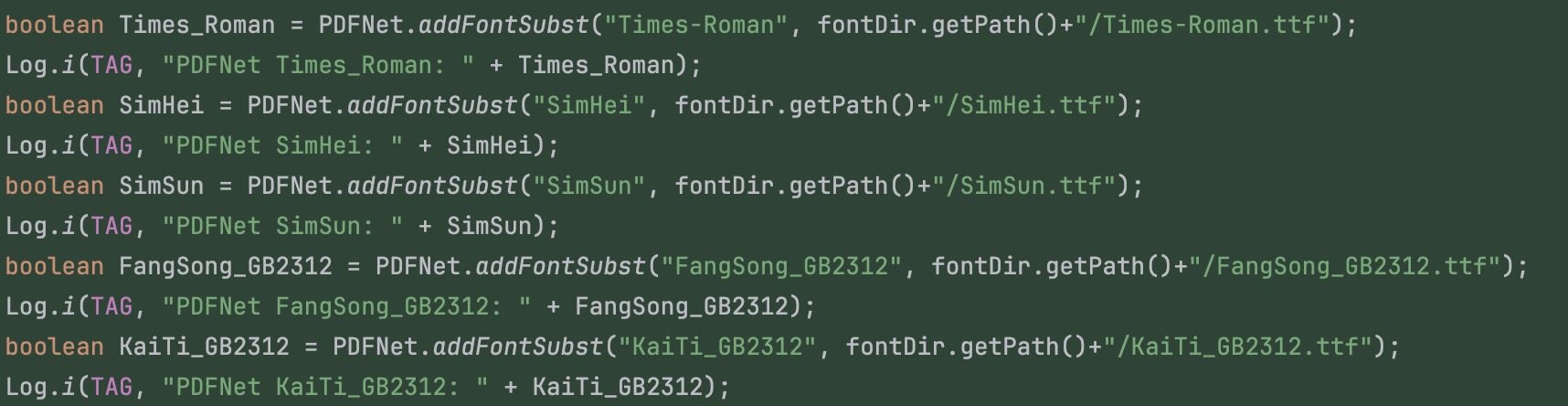
Use the Apryse SDK’s font substitution feature to substitute missing fonts with available ones on the device.
Experiment with different rendering modes or configurations in the SDK to see if they affect the display.
Here are some resources that might help you:
Font Handling in Apryse Android SDK: This guide provides information on how to manage fonts in your app, including substitution and embedding.
I have implemented the font substitution in my project as per the documentation, but unfortunately, the issue persists . The Chinese text still renders as garbled characters.
Here is a screenshot of the key parts of my implementation code for your further investigation. Critically, all font substitution methods returned true, demonstrating that the operation itself was technically successful.
Thank you for reaching out for support through our forum. It seems this is a malformed PDF. We would like to know how many other files have this issue? And if it is multiple files, are they all from the same source? I look forward to your response.
Number of affected files: So far, I have encountered this specific rendering issue with only this one particular PDF file provided by a client.
Source of the file: This problematic PDF was provided by a client. While I do not have other files from this same client to compare, this appears to be an isolated case among the documents I handle.
This aligns with your assessment that it is likely a malformed PDF. What makes this case noteworthy is that while such profoundly malformed files are not common, they do exist in the ecosystem. In Chinese developer communities and search results, similar issues of garbled text in PDFs are occasionally reported.
A key observation is that mainstream PDF readers in China (such as WPS Office and Foxit Reader) seem to implement automatic repair or robust fallback mechanisms for such files, allowing them to be displayed correctly. This likely explains why the client did not encounter the issue before handing off the file.
My key question is: Could you advise on the recommended approach within the Apryse SDK to handle such non-standard or malformed PDFs? Is there a configuration, a parsing mode (like a “robust parsing” flag), or a pre-processing API that we can employ to mimic the “auto-repair” behavior seen in other readers, ensuring maximum compatibility?
I look forward to your guidance on implementing a more resilient solution at the SDK level.
Normally, we suggest that for invalid PDFs such as this, you contact the author of the document and see if they can repair it. We do currently have an update to our font substitution in PDFNet SDK that is undergoing review that is likely related to this issue. After this fix, the hope is that the text should use the correct Chinese glyphs.
Please note that we cannot guarantee the output for invalid files, no vendor can, and I will update you again once an Android build is available for you to test.