WebViewer Version:
10.3.0
Do you have an issue with a specific file(s)?
NO
Can you reproduce using one of our samples or online demos?
NO
Are you using the WebViewer server?
NO
Does the issue only happen on certain browsers?
NO
Is your issue related to a front-end framework?
NO
Is your issue related to annotations?
YES
Please give a brief summary of your issue:
(Think of this as an email subject)
How to apply Reductions before display the document
Please describe your issue and provide steps to reproduce it:
(The more descriptive your answer, the faster we are able to help you)
Dear WebViewer Support Staff:
This is Asahi Hayakawa from FUJIFILM SOFTWARE Co., Ltd.
We are developing an online proofing service using PDFTron SDK,
and the requirement is to hide the specified area before display the whole document on screen for security.
We tried to use the reduction as the following, however all of these seems to have some problems:
【Try 1】
call 「viewerInstance.Core.annotationManager.applyRedactions」method in the 「documentLoaded」 event
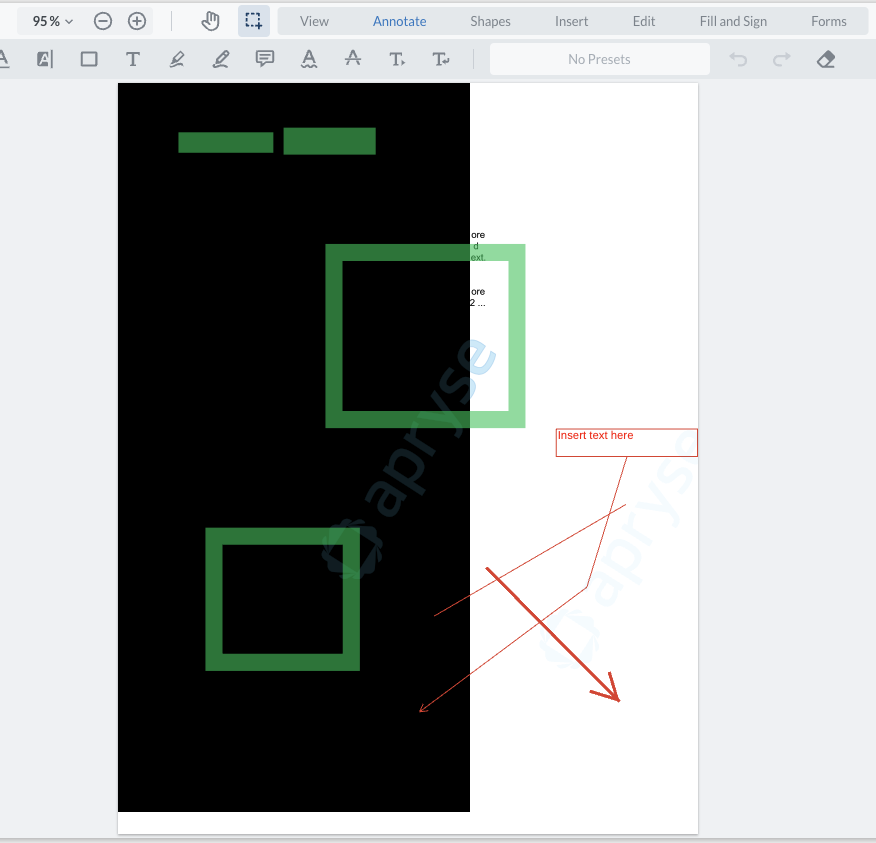
For pdf with a lot of pages, it seems that the page rendering is interfered by the redaction. As a result the blank pages are shown.
【Try 2】
call 「viewerInstance.Core.annotationManager.applyRedactions」method in the 「annotationLoaded」 event
It seems work this time but applyRedactions deletes the annotations overlapped with redaction annotations. We tried to redraw these annotations since it is necessary for users but it is not work. However, the redraw logic works perfectly when I did the same coding in documentLoaded event.
【Try 3】
call 「viewerInstance.Core.annotationManager.applyRedactions」method in the 「annotationLoaded」 event and redraw the annotations in 「documentLoaded」 event
Unfortunatly the area need to be hidden shows serval seconds when the pdf is large.
Can you help me about the problem?
if you need any further information please reply.
Thank you very much.
Please provide a link to a minimal sample where the issue is reproducible:
NO