Is it possible to merge XFDF file directly instead of coverting XFDF to FDF file before merging? As the annotations contains Chinese characters, it is supported only by XFDF file.
Hello, I’m Ron, an automated tech support bot 
While you wait for one of our customer support representatives to get back to you, please check out some of these documentation pages:
Guides:- Merge Form Data File (FDF) to PDF Forms using JavaScript
- Export annotations using JavaScript
- More full API PDF processing options - Annotations
- Full API samples for WebViewer - Console samples - XFDF Import
I’m not quite sure what you mean about “merge XFDF file”.
Merge to where?
Assuming you just want to merge the XFDF string into your document, you will somehow need to get ahold of the XFDF string and then call:
https://docs.apryse.com/api/web/Core.AnnotationManager.html#importAnnotations
More information can be found in this guide:
https://docs.apryse.com/documentation/web/guides/annotation/import-export/files/
Anthony Chen
Hi Anthony,
Thanks for your response.
What I wanted is to merge XFDF data into PDF file. Please see below sample code:
from PDFNetPython3 import *
# Import annotations from XFDF to FDF
fdf_doc = FDFDoc.CreateFromXFDF("fdf_field.xfdf")
fdf_doc.Save( "BlankCRF.fdf")
# Merge FDF data into PDF doc
doc = PDFDoc("BlankCRF.pdf")
doc.FDFMerge(fdf_doc)
doc.Save("numbered_modified.pdf", SDFDoc.e_linearized)
print("Merge complete.")
doc.Close()
As we can see, we need convert XFDF into FDF before merging. Is it possible to merge XFDF file directly? Thanks.
No, XFDF has to be converted to FDF first.
As the annotations contains Chinese characters, it is supported only by XFDF file.
It should also work fine in FDF.
Note that XFDF is always UTF8 encoded XML, so the issue might be that the encoding has been mangled. Since you are passing in a file path to CreateFromXFDF, then the XFDF file should be UTF8 encoded. If not, please either find out where the encoding is being changed and correct there, or convert it back to UTF8 before passing to CreateFromXFDF.
If the above does not help, then please provide us the XFDF string, with the Chinese characters, that you pass to CreateFromXFDF
Hi Ryan,
Many thanks for your response.
Seems it is not encoding issue. It is caused by format changed after converting from XFDF into FDF. That is there is no annotations in the converted FDF file. Please see below image.
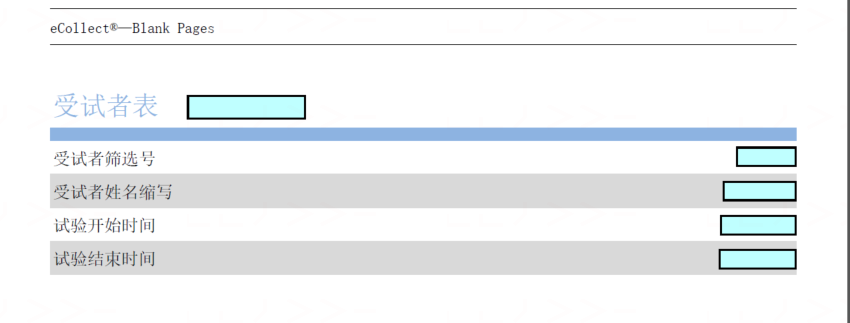
And the correct ouput should be look like below.
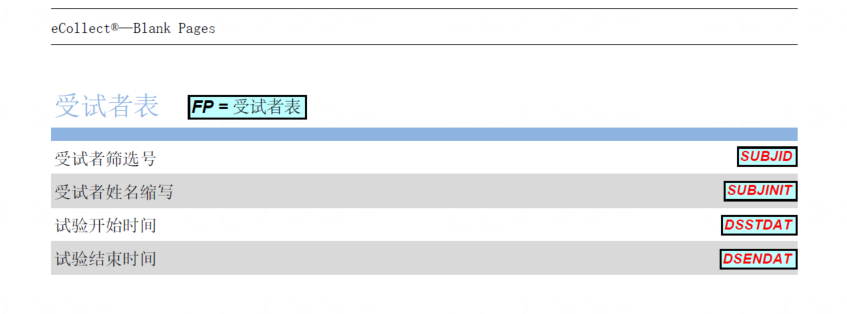
I compared the converted FDF file with the exported FDF file found the format was different. Please see the second field compare result below.
Coverted

Exported

As we can see, str ‘Contents(SUBJID)’ is missing in the coverted FDF file.
Please kindly download the sample files from below link as I am not able to upload the file. Thank you so much.
Thank you for the additional information. It looks like this XFDF is not from our SDK.
Do you know the source of the XFDF file?
What application generated it?
Also why is importing XFDF from another application important for you?
The XFDF is created by write statement in Python. I just want merge XFDF into PDF automatically instead of importing it manually. Note that both XFDF and coverted FDF file work fine when importing manually.
And even though I pass XFDF string to CreateFromXFDF, it still doesn’t work. please see below.
# Example 4
# Merge/Extract XFDF into/from PDF
from PDFNetPython3 import *
# Merge XFDF from string
in_doc = PDFDoc('BlankCRF.pdf')
in_doc.InitSecurityHandler()
print("Merge XFDF string into PDF.")
anno = '''<?xml version="1.0" encoding="UTF-8"?>
<xfdf xmlns="http://ns.adobe.com/xfdf/" xml:space="preserve"
><annots
><freetext color="#BFFFFF" name="1c28dc09-5063-494f-8fa1-6d4f3cf3119d" page="0" rect="132.128000,758,214.907180,775"
><contents-richtext
><body xmlns="http://www.w3.org/1999/xhtml" style="font-size:12 pt;text-align:left;color:#000000;font-weight:bold; font-style:italic;font-family:Arial;font-stretch:normal"
><p dir="ltr"
>FP = 受试者表</p
></body
></contents-richtext
><defaultstyle
>font: Helvetica,sans-serif 12.0pt; text-align:left; color:#000000 </defaultstyle
></freetext
><freetext color="#BFFFFF" name="e8fbe12f-9e4b-47a7-932e-45979c1c7283" page="0" rect="516.618462,724.820000,559,738.808000"
><contents-richtext
><body xmlns="http://www.w3.org/1999/xhtml" style="font-size:10 pt;text-align:left;color:#FF0000;font-weight:bold; font-style:italic;font-family:Arial;font-stretch:normal"
><p dir="ltr"
>SUBJID</p
></body
></contents-richtext
><defaultstyle
>font: Helvetica,sans-serif 12.0pt; text-align:left; color:#000000 </defaultstyle
></freetext
><freetext color="#BFFFFF" name="a87a654a-3fbd-4050-af5b-75e8b2ac1f96" page="0" rect="507.322037,700.900000,559,714.888000"
><contents-richtext
><body xmlns="http://www.w3.org/1999/xhtml" style="font-size:10 pt;text-align:left;color:#FF0000;font-weight:bold; font-style:italic;font-family:Arial;font-stretch:normal"
><p dir="ltr"
>SUBJINIT</p
></body
></contents-richtext
><defaultstyle
>font: Helvetica,sans-serif 12.0pt; text-align:left; color:#000000 </defaultstyle
></freetext
><freetext color="#BFFFFF" name="b18d16ad-0c14-443e-ad1b-f97b36b9d9ed" page="0" rect="505.585612,676.970000,559,690.958000"
><contents-richtext
><body xmlns="http://www.w3.org/1999/xhtml" style="font-size:10 pt;text-align:left;color:#FF0000;font-weight:bold; font-style:italic;font-family:Arial;font-stretch:normal"
><p dir="ltr"
>DSSTDAT</p
></body
></contents-richtext
><defaultstyle
>font: Helvetica,sans-serif 12.0pt; text-align:left; color:#000000 </defaultstyle
></freetext
><freetext color="#BFFFFF" name="2f6e6c0b-1fd1-4cd0-9b65-eefd3b4e8d23" page="0" rect="504.414345,653.050000,559,667.038000"
><contents-richtext
><body xmlns="http://www.w3.org/1999/xhtml" style="font-size:10 pt;text-align:left;color:#FF0000;font-weight:bold; font-style:italic;font-family:Arial;font-stretch:normal"
><p dir="ltr"
>DSENDAT</p
></body
></contents-richtext
><defaultstyle
>font: Helvetica,sans-serif 12.0pt; text-align:left; color:#000000 </defaultstyle
></freetext
></annots
><f href="BlankCRF.pdf"
/><ids original="0FE6549795F517C91D6F3DB8621AB972" modified="935D35EEEADFCB4583AE037128E40BA8"
/></xfdf
>
'''
fdoc = FDFDoc.CreateFromXFDF(anno)
in_doc.FDFMerge(fdoc)
in_doc.Save('numbered_modified.pdf', SDFDoc.e_remove_unused)
in_doc.Close()
print("Merge complete.")
Seems above XFDF format is not supported by PDFNetPython3? Can you please provide the XFDF format supported by PDFNetPython3? Many thanks.
This appears to be an issue in the SDK that we need to address. A fix is being reviewed, and I will let you know when it is available. In the meantime, thank you for your patience.
Thank you so much. I am looking forward to see the update.
The fix is currently in our server side developer preview builds. It will be a while longer before it will be available in production WebViewer builds.
Is this issue a blocking issue for you?
If so, what is your next deadline?
Thanks for updating me. Actually it is not blocking issue for me. As currently I used an alternative way. That is adding statement><f href="BlankCRF.pdf" at the end of XFDF file. In this case when I double click on XFDF, BlankCRF.pdf will be opened automatically. This is a devious way so I am still looking forward to see the update.
Hi Ryan,
Just want to check with you if the update was done. Thank you.
Alian