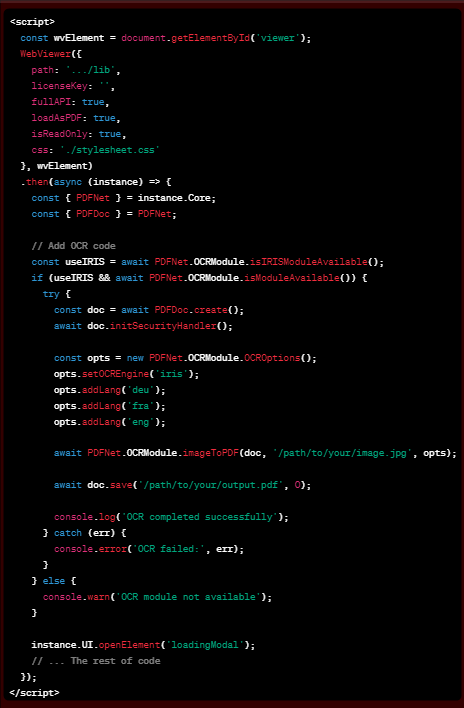
Text extraction, of whatever text is in a PDF, is client side yes. This would include any text added by any previous OCR.
But if you are talking about actually doing OCR processing (adding text to an image based PDF) then that is only available server side. The OCR module is not available client side only.
If you are indeed asking about the latter, perhaps you could elaborate on why doing an OCR pass on an image/PDF client side in the browser is important for your users?
I’m currently working on enhancing the document comparison feature, specifically focusing on allowing users to compare two documents, either of which may contain an OCR layer from a previous operation. To achieve this, it seems like I need to incorporate the following code into the webViewer instance. 1)Is this functionality on the client side or does the server component have to be installed? 2)and the code is correct?
Looking forward to your guidance on implementing this.
While I don’t encounter any issues with the comparison process itself, my concern lies in the handling of a document with an OCR layer. In the provided source code, the solution involves extracting the OCR layer. Could you clarify whether this extraction process occurs client-side or requires a server?
Additionally, I’m curious whether I can incorporate the extraction code into a webViewer instance, or if a separate application is necessary. My ultimate goal is to obtain an output that can be utilized for the comparison process.