Product: PDFNetRuby and PDFNetPython
Product Version: 10.1
Please give a brief summary of your issue:
Ever-growing memory usage with StreamingPDFConversion. Wondering if I’m overlooking something and missing other necessary cleanup.
Please describe your issue and provide steps to reproduce it:
We noticed our app crashing with errors related to bad memory allocation. To try to isolate our testing, I did some memrory profiling with a simple script and I think it might be an issue in the SDK. It might be that I’m missing some necessary cleanup so would love to show you what I did and maybe you can help fill in the gaps on my end. Here is the script used for testing.
# frozen_string_literal: true
# rubocop:disable all
require '/usr/local/PDFNetC/Lib/PDFNetRuby'
PDFNetRuby::PDFNet.Initialize(ENV.fetch('PDFTRON_LICENSE_KEY'))
def convert(filepath, ident)
puts "[#{ident}] Converting #{filepath}"
extension = File.extname(filepath)
opts = PDFNetRuby::ConversionOptions.new
opts.SetFileExtension(extension)
conv = PDFNetRuby::Convert.StreamingPDFConversion(filepath, opts)
result = conv.TryConvert
unless result == PDFNetRuby::DocumentConversion::ESuccess
raise conv.GetErrorString
end
doc = conv.GetDoc
conv.Destroy
doc.Lock
doc.Save("#{filepath}.#{ident}.pdf", PDFNetRuby::SDFDoc::E_linearized)
doc.Unlock
doc.Close
end
filepath = ARGV.first
10_000.times do |x|
convert(filepath, x)
end
I ran this with a test .docx file of 168 pages with 91688 words of lorem ipsum text. Here is what I observed:
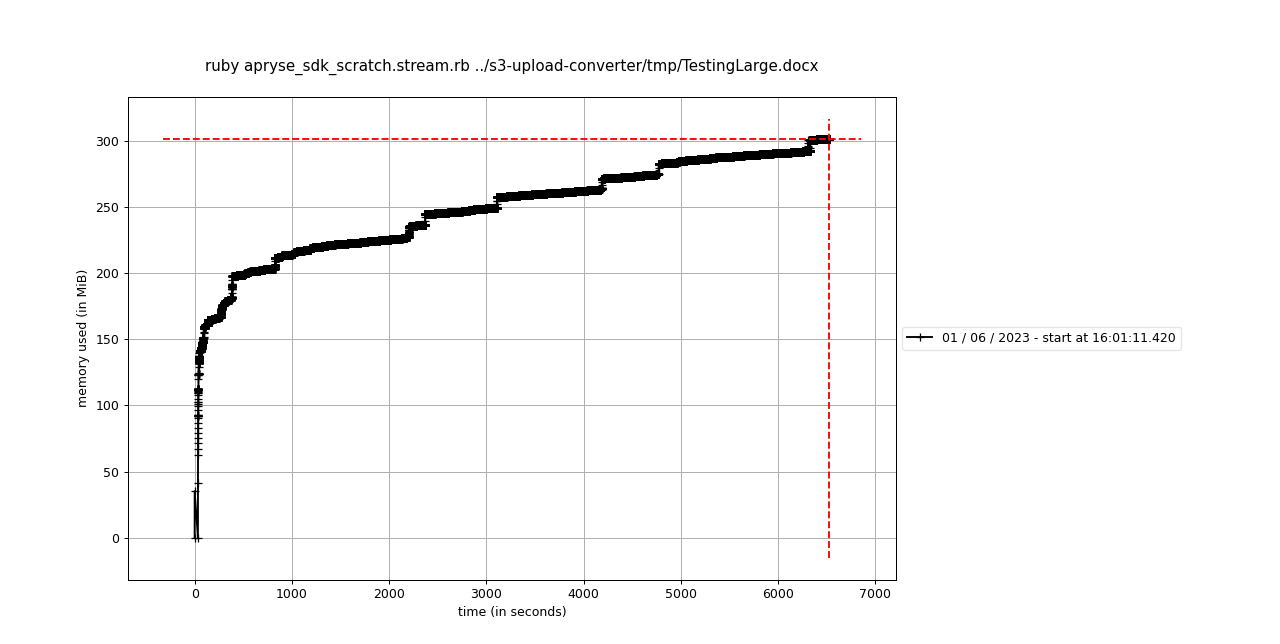
So throughout the 1.5 hours, the memory usage is essentially increasing linearly and went up as high as 300MiB by the time it converted the file 10000 times.
As a comparison, I ran a similar test with OfficeToPDF and it doesn’t appear to have this problem. Here is the script modified to use OfficeToPDF:
# frozen_string_literal: true
# rubocop:disable all
require '/usr/local/PDFNetC/Lib/PDFNetRuby'
PDFNetRuby::PDFNet.Initialize(ENV.fetch('PDFTRON_LICENSE_KEY'))
def convert(filepath, ident)
puts "[#{ident}] Converting #{filepath}"
extension = File.extname(filepath)
doc = PDFNetRuby::PDFDoc.new
PDFNetRuby::Convert.OfficeToPDF(doc, filepath, nil)
doc.Lock
doc.Save("#{filepath}.#{ident}.pdf", PDFNetRuby::SDFDoc::E_linearized)
doc.Unlock
doc.Close
end
filepath = ARGV.first
10_000.times do |x|
convert(filepath, x)
end
I ran this with the same .docx file. Here is the result:
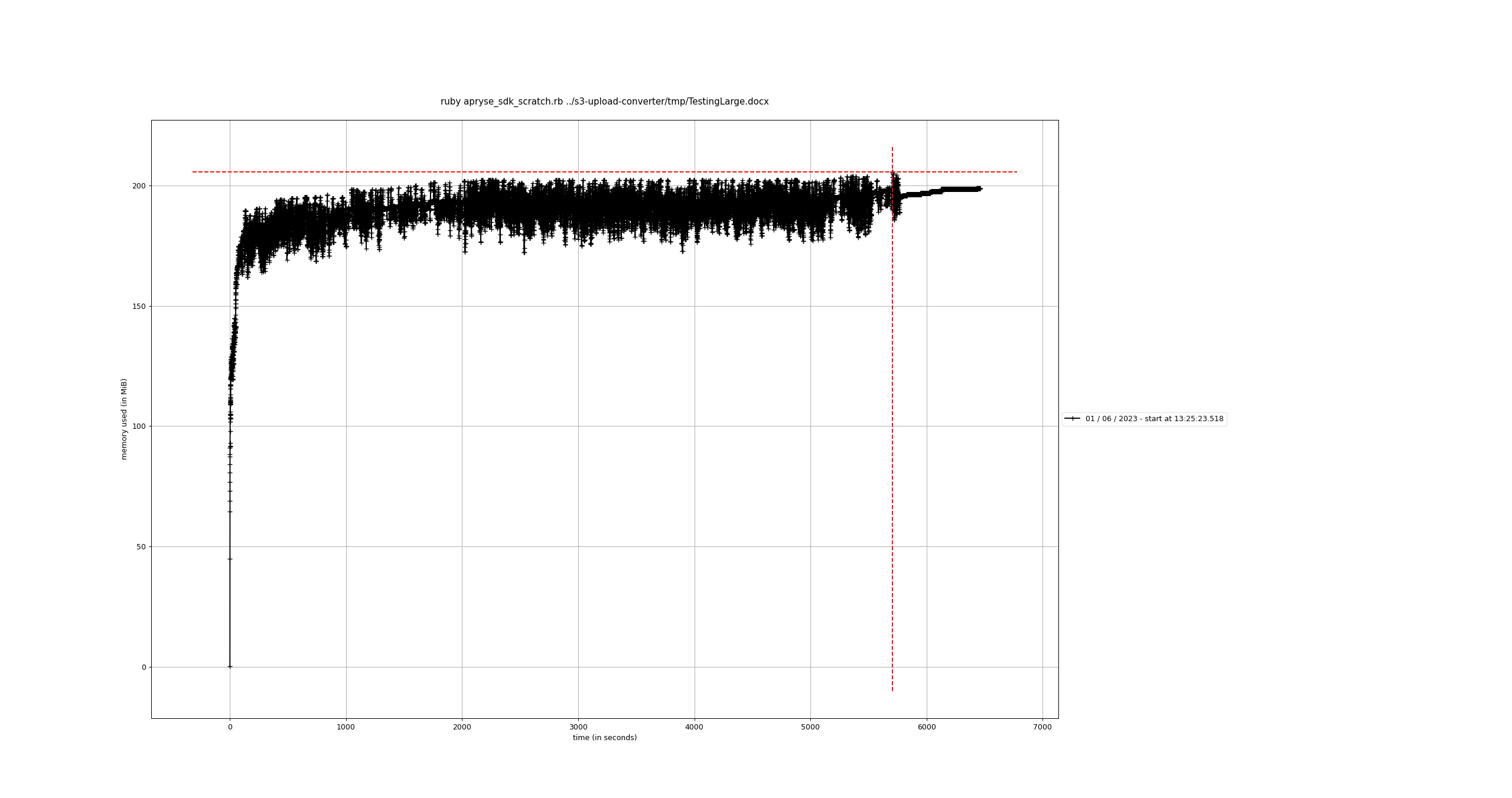
This time, the memory usage is up to a bit over 200MiB but hovers around there throughout most of the runtime. 200MiB still seems a bit high (the test .docx file is only 100KB) but at least it appears to level off.
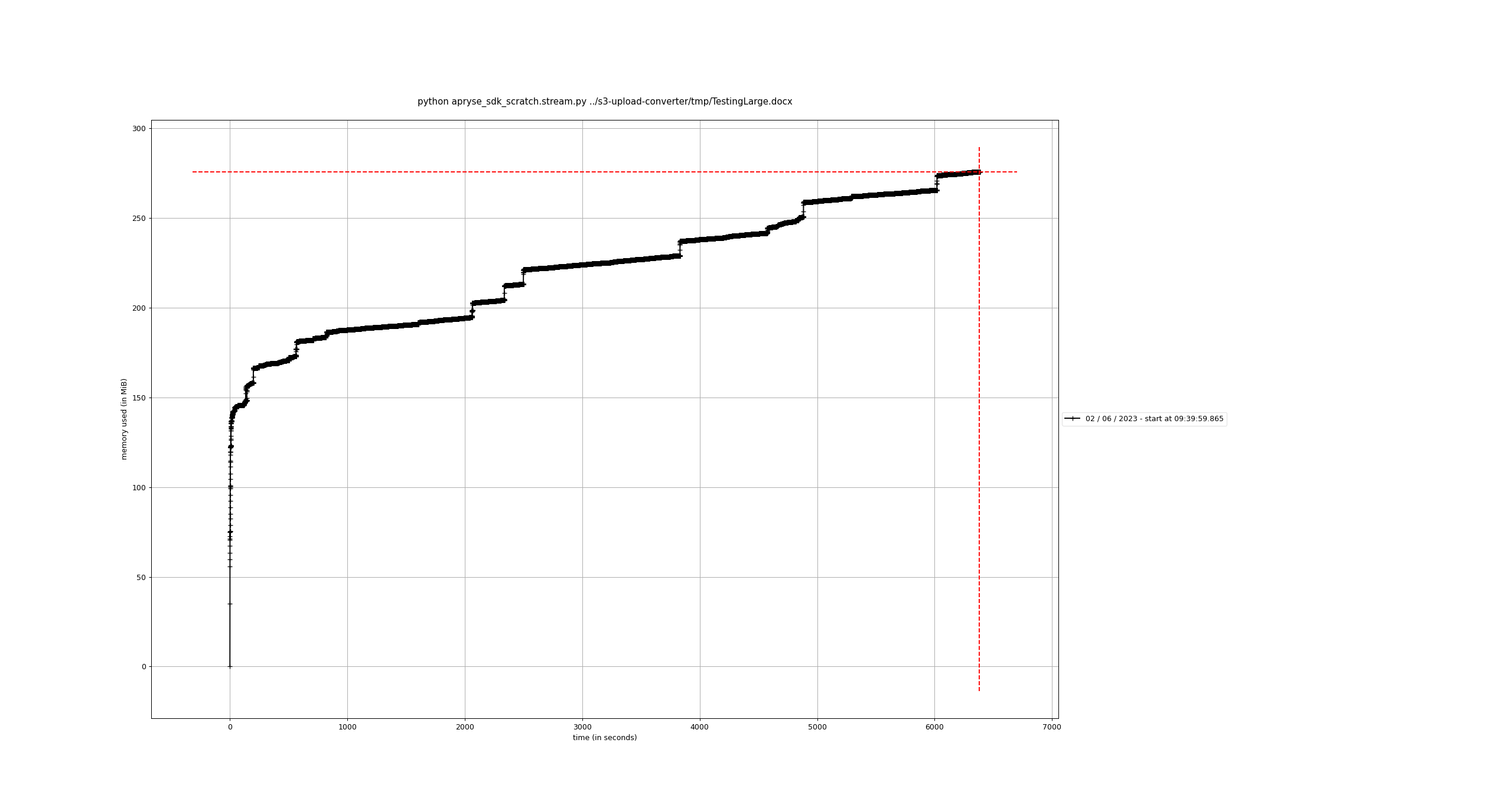
Out of curiosity, I wrote similar Python scripts to just make sure the problem wasn’t in just Ruby. Here is the script and results from StreamingPDFConversion:
from apryse_sdk import *
import os
import sys
class ConversionError(Exception):
pass
PDFNet.Initialize(os.environ['PDFTRON_LICENSE_KEY'])
def convert(filepath, ident):
print(f'[{ident}] Converting {filepath}')
_, extension = os.path.splitext(filepath)
opts = ConversionOptions()
opts.SetFileExtension(extension)
conv = Convert.StreamingPDFConversion(filepath, opts)
if conv.TryConvert() != DocumentConversion.eSuccess:
raise ConversionError(conv.GetErrorString)
doc = conv.GetDoc()
conv.Destroy()
try:
doc.Lock()
doc.Save(f'{filepath}.{ident}.pdf', SDFDoc.e_linearized)
doc.Unlock()
finally:
doc.Close()
filepath = sys.argv[1]
for x in range(0, 10000):
convert(filepath, x)
The script and results with OfficeToPDF:
from apryse_sdk import *
import os
import sys
class ConversionError(Exception):
pass
PDFNet.Initialize(os.environ['PDFTRON_LICENSE_KEY'))
def convert(filepath, ident):
print(f'[{ident}] Converting {filepath}')
_, extension = os.path.splitext(filepath)
doc = PDFDoc()
Convert.OfficeToPDF(doc, filepath, None)
doc.Lock()
doc.Save(f'{filepath}.{ident}.pdf', SDFDoc.e_linearized)
doc.Unlock()
doc.Close()
filepath = sys.argv[1]
for x in range(0, 10000):
convert(filepath, x)
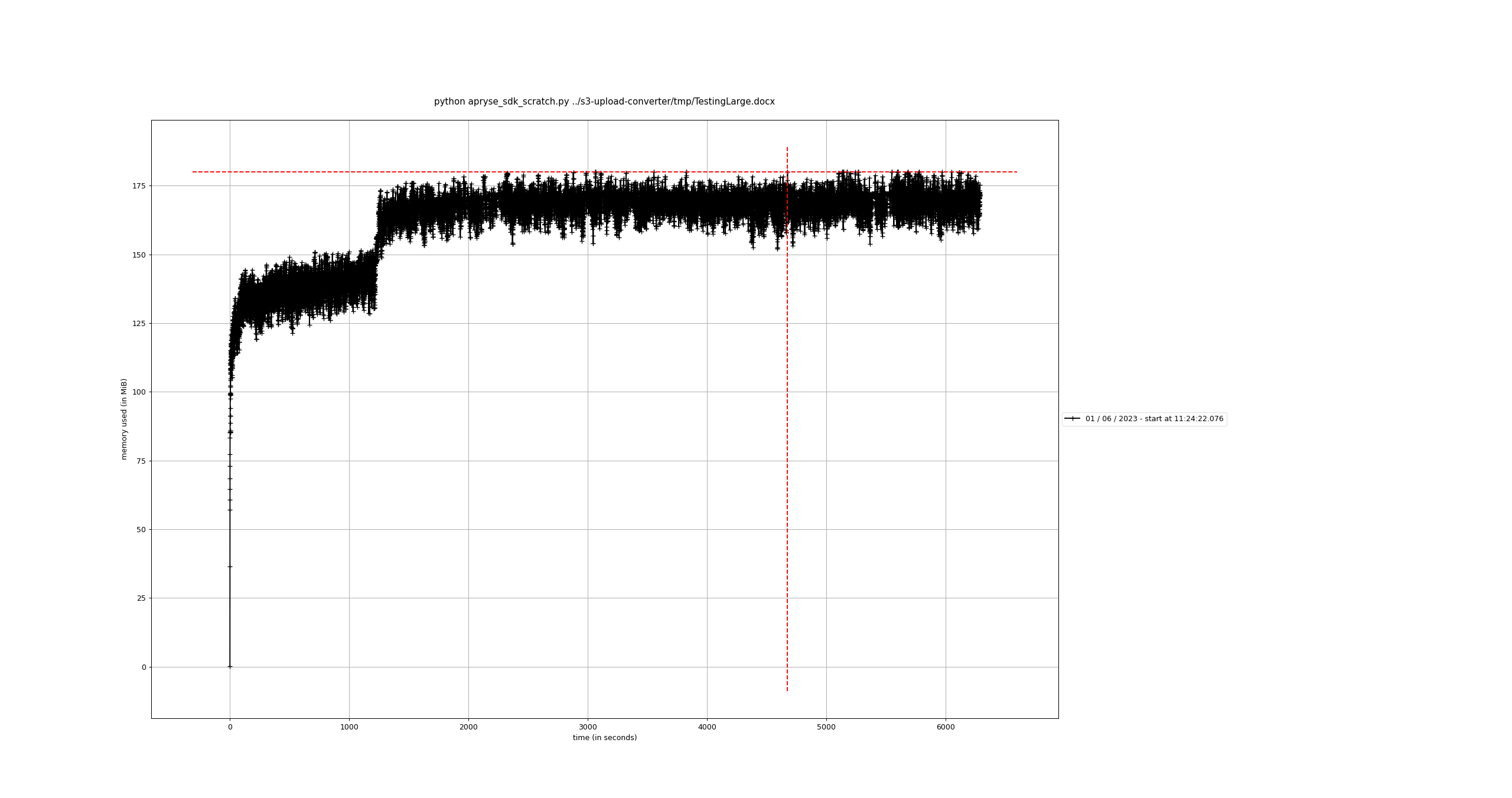
As you can see, the behaviors are similar from both the Ruby and Python SDKs. Ruby is showing a bit more memory usage but I think that’s probably just due to their respective memory management approaches (GC vs. RC).
With our use case, we can stick to OfficeToPDF since that can still address our current needs. However, I’d like to know if there is anything else I should be doing to see better memory usage with StreamingPDFConversion.
These tests were run with Ruby 3.1.4 and Python 3.11.3. The RubySDK was compiled with your PDFNetWrappers tool. The Python SDK was installed from your index at https://pypi.apryse.com.
Please provide a link to a minimal sample where the issue is reproducible:
See code and results above.