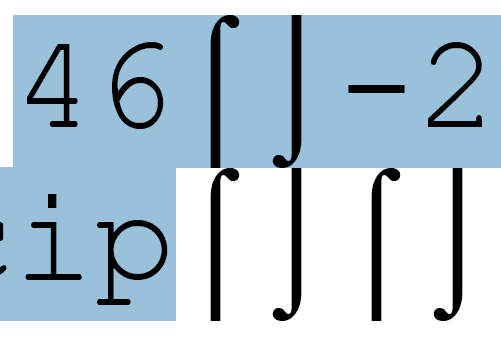I’m building a tool which relies on the user selecting text, and having that text extracted and piped into other features. Some PDFs seem to render with a pretty large “line height”, so much so that the selectionbox is overlapping the line above or below, and the letters that intersect are also extracted as a result.
For example the below selection extracts the text: “considerationit di t”. Because the dots on the i and the top of t’s are included in the selection box.
This also results in a strange behaviour when double clicking to select a word if you do it in the overlap area:
As you see the overlap is quite big.
Additionally in Adobe it shows as:
Now I realize determining the exact size of text in 100% of pdf documents is tricky and hard to solve. But I’m wondering if there’s any way for me to hook into the selection process and apply some transformations that would solve this issue for our use cases. I’m already doing things with the resulting quads from a selection to make sure the rest of the process runs smoothly, but I’d like to go one step further back and tweak the actual selection if that’s possible.
I used this file in the demo site and it’s the same behaviour. It’s not a custom feature but just the way PDFTron tries to determine the font heights internally. Something about this PDF confuses PDFTron. I have since seen the same in other files too, and even noticed the same issue slightly in a screenshot in the PDFTron guides: the second image here, if you look closely, you’ll see the selection boxes overlap somewhat: https://www.pdftron.com/documentation/web/guides/extraction/selected-text/. It’s probably really close here to extracting that first L on the second line within the first quad as well.
I’ve attached the file that shows it best. A little bit of overlap doesn’t really have a lot of impact, but the amount I see in this file is quite bothersome, especially since it reaches the other text. We’re using this to redact content, and those t’s and i’s sneaking into the quad above makes it that they themselves get redacted too. Of course if you could solve it natively that would be great, otherwise I’ll be looking for the cleanest workaround.
Thanks for providing the file. I have partially reproduced this issue using the file.
Selected “line height” does seem to be overlapping for some PDFs, I’ve added the issue to our backlog to be worked on in the future. We don’t have a timeline for when it will be fixed but if it does get fixed we’ll let you know when it’s available in an experimental build to test out and the estimated official release date. If you have a desired timeline for having this issue fixed please let us know and we’ll do our best to work with you on how this can fit into the WebViewer release schedule.
However, When I used the following code snippet to extract selected text, webviewer returned the correct selected text (although visually the selected ‘line height’ overlaps with other lines sometimes):
documentViewer.addEventListener('textSelected', (quads, selectedText, pageNumber) => {
// quads will be an array of 'Quad' objects
// text is the selected text as a string
if (selectedText.length > 0) {
console.log(selectedText);
}
});
Could you confirm on your side if selectedText is working as intended?
Please let me know how this works for you, and I look forward to hearing from you.
Best Regards,
Jason Hu
Web Development Support Engineer
PDFTron Systems, Inc.
Thanks for looking into it. We’re not actually using the textSelected event, because it fires on every selection change. Instead we use the selectionComplete event on the textselection tool. I can confirm that textSelected extracts the right text, but unfortunately the selectionComplete event only passes the appropriate quads and not the text. When using those quads to extract text via PDFNet, the overlap will get in the way. Even if we would switch to the other event, the quads will still be too large and the redaction processor will remove whatever else it’s overlapping.
We do have a manageable workaround for now by shrinking the quads a little bit, both for text extraction as well as creating the redaction annotation. Visually it’s not that noticeable, but when using a file where the selection box is exactly right, a user might think you’d still be able to see the tops of letters if the redaction box is slightly smaller (which of course, you wouldn’t be). Like I said; manageable.
As for a timeline, we’re hoping to ship this out in a month or two. We’ll need to test some more representative pdf’s to see how big this issue is in the field, I really can’t say at the moment.
You mentioned you could partially reproduce the issue; is there anything that I can clear up for you?
Thank you for your detailed response. It is good to see that you have a reasonable workaround. The bug is currently on our backlog, hopefully it will be picked by one of the developers. If no one takes it after two weeks or three weeks, I will look into the problem. I am sorry that I can not investigate the issue now, as I have other tasks at hand, but I will try my best to commit a fix within four weeks.
“You mentioned you could partially reproduce the issue; is there anything that I can clear up for you?”
I mentioned this because I could not reproduce the werid extracted text issue, as I used ‘textSelected’ event to extract text and I did get the correct extracted text. As you mentioned that you used ‘selectionComplete’ and PDFNet to etract text, now I could see why you are getting the described text extraction in the original post.
I’ll keep this ticket open for now, if there is anything you would like to add, you can directly reply to this ticket. Thank you for your patience.
Please let me know how this works for you and if you have any other questions.
Best Regards,
Jason Hu
Web Development Support Engineer
PDFTron Systems, Inc. www.pdftron.com
I took a deeper dive last week and found that the codes responsible for “textSelection” tool were directly transpiled from C++ or/and Java. So this problem is beyond the reach of the WebViewer team. I will pass on the problem to the Core team, and they will investigate further.
Meanwhile, thank you for your patience.
Best Regards,
Jason Hu
Web Development Support Engineer
PDFTron Systems, Inc. www.pdftron.com
Sounds like a nice can of worms Thank you for your efforts so far. We’re not live yet so we haven’t come across this issue in real life yet, but it does turn some heads during demo’s if we happen to pick the “wrong” test file. I’ll be curious to see if the Core team can get any results.
Thank you for your understanding, our core team found that we are taking the largest “glyph size” of any particular fonts.
The largest glyph in a font can be significantly taller than average. Especially in math fonts. The sum/integral symbol is multiple times taller than the letter ‘a’. And if the tallest glyph is never used, it significantly enlarges the line bbox. Basically the Max Glyph Size overwrites all vertical quad coordinates. Each glyph is considered as tall as the largest glyph.
It’s very hard to reverse engineer what Adobe is doing, we are thinking of offering some form of dual-mode approach(The tightest box around the line glyphs and largest glyph modes) for different proposes. Meanwhile, if you have any new findings, please feel free to let us know :D.
Best Regards,
Jason Hu
Web Development Support Engineer
PDFTron Systems, Inc. www.pdftron.com
Thanks for keeping me informed! Very interesting indeed, I’m wondering how it would look if you put those largest glyphs above each other, they would need to overlap. I did a small test but couldn’t make it happen; these glyphs are also smaller than the bbox in pdftron, so they’re probably not the ones stretching it:
Found it interesting though how adobe seems to line it up pixel perfect.
In our case specifically it wouldn’t really matter how tight the bbox is vertically. Even if it doesn’t contain all the glyphs and some letters/symbols stick out of the bbox, the text extraction would still count that intersect and extract the right results. Personally I think that offers a better user experience than accidentally selecting multiple lines.
Another way you might solve it is by using the coordinates for the next line. If you know how far below the next line is you might be able to calculate how much space there is in between, and cap out the bboxes so they don’t overlap.
Is this something the core team will be working on, or is not on a timeline yet?
Thank you for the suggestion, I have passed it onto the core team.
I am with you that tighter bboxes would produce better results sometimes. However, there is no real one-fit-all solution here, so that is why we think offer both solutions would be better. We are constantly improving our products and trying our best to reach the “golden standard” for PDF(and other documents in general) viewing. Meanwhile, we thank you for your understanding :D.
Because text selection codebase is very complex and requires a lot of testing, so unfortunately we don’t have a timeline for this yet. Hopefully, this will be worked on soon, as it does improve many users’ experience.
We will keep you posted on the latest development of such feature.
Best Regards,
Jason Hu
Web Development Support Engineer
PDFTron Systems, Inc. www.pdftron.com




 Thank you for your efforts so far. We’re not live yet so we haven’t come across this issue in real life yet, but it does turn some heads during demo’s if we happen to pick the “wrong” test file. I’ll be curious to see if the Core team can get any results.
Thank you for your efforts so far. We’re not live yet so we haven’t come across this issue in real life yet, but it does turn some heads during demo’s if we happen to pick the “wrong” test file. I’ll be curious to see if the Core team can get any results.