Product:
PDFTron Webviewer
Product Version:
8.8.0
Please give a brief summary of your issue:
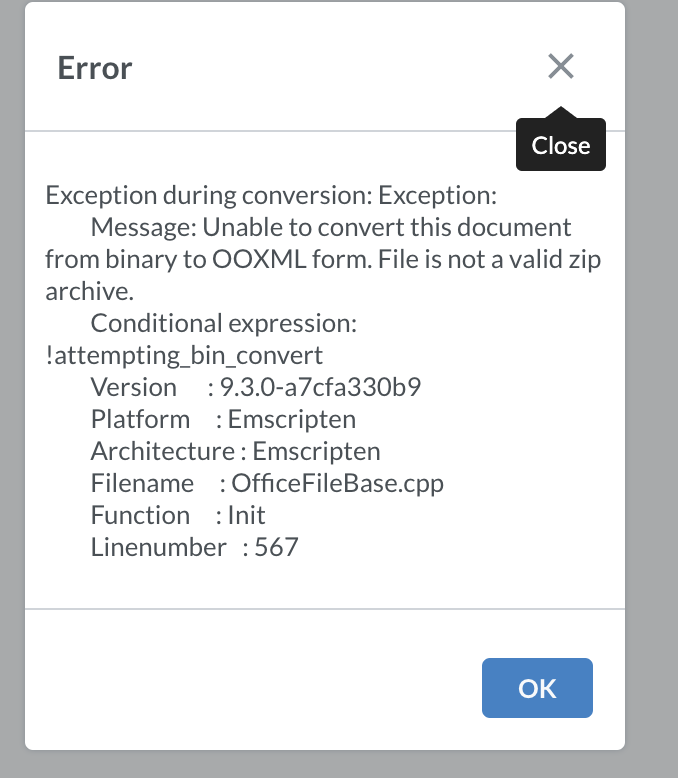
Unable to convert this document from binary to OOXML file is not a valid zip archive
Please describe your issue and provide steps to reproduce it:
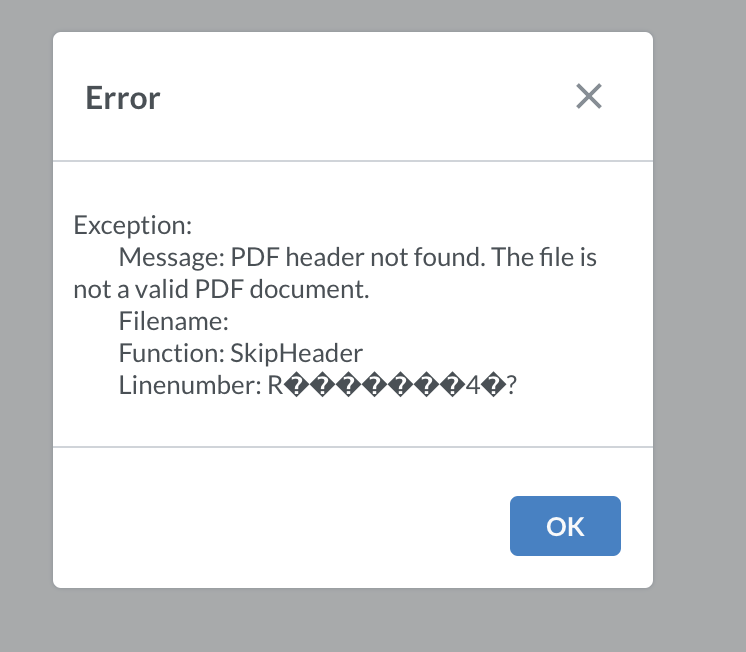
Unable to convert this document from binary to OOXML file is not a valid zip archive. This issue is happening to the demo version i deployed on an IIS server of which the same code was running fine on my machine before deploying it is happening for all the file types word and excel then for pdf files its writing: Message: PDF header not found. the file is not a valid PDF file of which i can open these files with other document viewing applications
Please provide a link to a minimal sample where the issue is reproducible:
If I am understanding correctly, you are trying to convert a binary document to an office document on WebViewer? Which demo are you following for the conversion?
Here are the currently supported file formats for WebViewer:
The exception you see is because the file you are trying to open is not a PDF, you can see a related forum post here:
Best Regards,
Kevin Kim
Web Development Support Engineer
PDFTron Systems, Inc. www.pdftron.com
Below is the code snippet that i’m using angular integration with WebViewer, The logic is successfully loading on my PC but giving issues when deployed on IIS Server
hi @leonmuzire96 did u manage to fix this problem? I have been getting the same error, every time i change the URL/filepath when reading a DOCX file, but when i load the file at the start if loads fine it just pups every time it changes.
If it works, then there’s something wrong with extension of the file.
For example, maybe the content your office file is not an office file, but PDF file. If you try to open a PDF file whole name is document.docx, then you pass ‘docx’ to ‘extension’ option, then you will get the ‘Exception during conversion’ error.
On the other hand, if your filename is document.pdf, but the content inside is docx, you will get error PDF header not found.
did you use WebViewerOption ‘extension’ ???
If not, WebViewer will guess the file extension from your URL. If the URL does not contain extension, then it will assume the file is PDF.
I came across this problem with a file that opened perfectly if specified as initalDoc, but failed if loaded via instance.UI.loadDocument - I tracked it down to the relative paths, and the loadDocument method not actually being able to find the file.