I’m currently working on a proof-of-concept that involves using PDFTron for viewing and signing PDFs.
I’m working on creating some unit tests related to parsing the PDF for particular values, but I’m not sure how to setup the tests. Below is a sample of where I’m currently at with it. When I run the test, the Jest timeout is always reached, regardless of how long I set the timeout to be.
import WebViewer, { WebViewerInstance, WebViewerOptions } from "@pdftron/webviewer";
import "jest-canvas-mock";
import { extractTitle } from "./parser";
const testPdfPath = "./public/files/sample1.pdf";
async function setupInstance(): Promise<WebViewerInstance> {
const options: WebViewerOptions = {
filename: "sample.pdf",
fullAPI: true,
initialDoc: testPdfPath,
loadAsPDF: true,
path: testPdfPath,
};
const div = document.createElement("div");
const instance = await WebViewer(options, div);
return instance;
}
describe("extractTitle", () => {
it("correctly finds the title of a simple document", async () => {
// Arrange
const expected = "PDFTron Sample PDF Text Tag Document 2";
const instance = await setupInstance();
const doc = await instance.Core.documentViewer.getDocument().getPDFDoc();
const page = await doc.getPage(1);
const txt = await instance.Core.PDFNet.TextExtractor.create();
const rect = await page.getCropBox();
txt.begin(page, rect);
const line = await txt.getFirstLine();
const docTitle = "";
const parsedData = {};
// Act
const actual = await extractTitle(line, docTitle, parsedData);
// Assert
expect(actual).toEqual(expected);
});
});
Is there a sample web repository that includes unit tests that I could reference?
Do you know what line the code stop working on? I think the issue is you are passing WebViewer an element that doesn’t exist in the DOM yet. I think you’ll need to do something like
and after each test you’ll need to clean up by deleteing that element from the DOM.
Besides that, another possible issue I see is you might be calling “getPDFDoc” before the document has been loaded, so you’ll need to change your test to wait for the documentLoaded event. documentLoaded
Please let me know if the above helps or if you have any other questions
Best Regards,
Andrew Yip
Software Developer
PDFTron Systems, Inc. www.pdftron.com
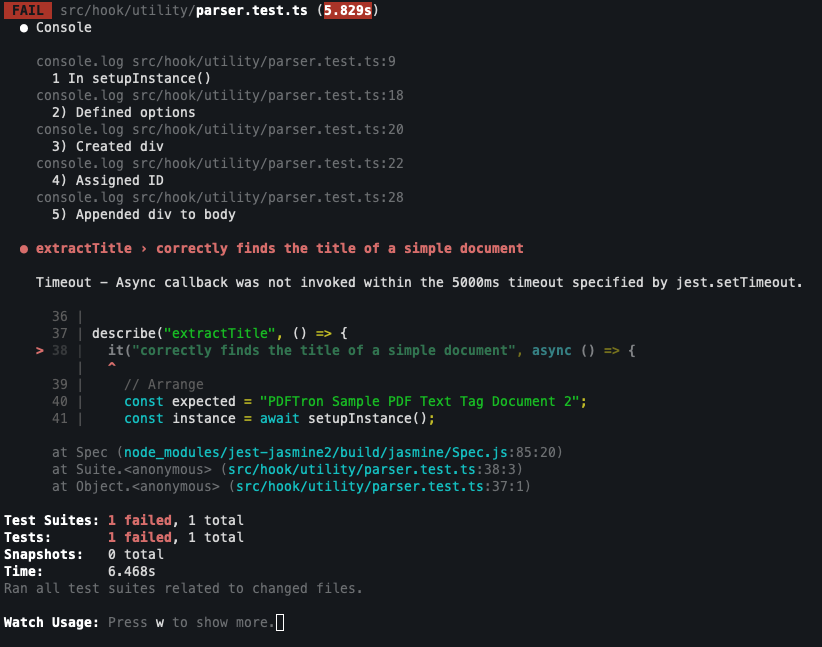
Thanks for taking a look! I tried both of your suggestions without any luck. Below is a sample of the updated code. The jest output is attached as an image. The test made it to “5) Appended div to body” but didn’t make it to “6) Done initializing WebViewer” or “documentLoaded”.
import WebViewer, { WebViewerInstance, WebViewerOptions } from "@pdftron/webviewer";
import "jest-canvas-mock";
import { extractTitle } from "./parser";
const testPdfPath = "./src/assets/sample.pdf";
const licenseKey = "demo:";
async function setupInstance(): Promise<WebViewerInstance> {
console.log("1 In setupInstance()");
const options: WebViewerOptions = {
filename: "sample.pdf",
fullAPI: true,
initialDoc: testPdfPath,
licenseKey,
loadAsPDF: true,
path: testPdfPath,
};
console.log("2) Defined options");
const div = document.createElement("div");
console.log("3) Created div");
div.id = "test";
console.log("4) Assigned ID");
const body = document.querySelector("body");
if (body === null) {
console.log("5) Unable to append div to body: Body is null");
} else {
body.appendChild(div);
console.log("5) Appended div to body");
}
const instance = await WebViewer(options, div);
console.log("6) Done initializing WebViewer");
return instance;
}
describe("extractTitle", () => {
it("correctly finds the title of a simple document", async () => {
// Arrange
const expected = "PDFTron Sample PDF Text Tag Document 2";
const instance = await setupInstance();
instance.Core.documentViewer.addEventListener("documentLoaded", async () => {
console.log("documentLoaded");
const doc = await instance.Core.documentViewer.getDocument().getPDFDoc();
const page = await doc.getPage(1);
const txt = await instance.Core.PDFNet.TextExtractor.create();
const rect = await page.getCropBox();
txt.begin(page, rect);
const line = await txt.getFirstLine();
// Act
const actual = await extractTitle(line);
// Assert
expect(actual).toEqual(expected);
});
});
});
Sorry for the delayed response, it looks like the issue is a bit more complex than I first thought. What does your testing framework look like? Are you using something like Puppeteer or Selenium? How are you handling the “window” object, are you mocking it? Also what are you planning to test, is it mostly APIs for processing the documents or is it more like integration testing to make sure everything works?
One issue with testing WebViewer is that it dynamically fetch resources (it does it from the “path” you pass in, so that path need to be publicly accessible). I think the current issue could be WebViewer is unable to fetch those resources. If you are using a testing framework that has a “non headless” mode (so you can see what is happening), you can check the network tab to see if WebViewer is able to fetch resources.
One approach would be to host WebViewer somewhere, (so running something like "npm run start" before running your test or use a test suit that can do that for you). Also if your test suit is able to, you can navigate to a page with WebViewer, but this start feeling like integration testing instead of unit testing
Let me know if the above help and more information about your test suite. Thank you
Best Regards,
Andrew Yip
Software Developer
PDFTron Systems, Inc.
Right now, we’re just doing standard unit testing (running under NodeJS) with Jest, but it sounds like we’ll need to do something with a headless browser to be able to test some of the code.
I’ll regroup with the team and let you know if I have any other questions.
Feel free to let us know if you have any other questions.
Internally we are able to unit test each component of our code (i.e. AnnotationHistoryManager, DocumentViewer, etc) and have a set up for integration testing (we use a headless browser for this). However, for you, your unit testing would be more similar to what we are doing for our integration testing (since the code has been minified and compiled together). So you’ll probably need a headless browser.
For unit testing, we have a guide for running our web SDK without the viewer, which might be helpful for unit testing if you are testing processing and parsing documents without needing to render them. You’ll still need to run Core.setWorkerPath('path to worker resources'); to a valid path for our SDK to retrieve resources Run without viewer
Also, I noticed that you are using some of our “full API” (getPDFDoc) and Core.PDFNet APIs. If you are mainly unit testing processing and parsing documents with our PDFNet APIs, you could make your test suite with our node.js SDK (in this case you don’t need to have a headless browser) node js SDK
The SDKs aren’t exactly the same (one is running in the browser environment while the node js one will be server-side) but the APIs are similar enough that you could use it to check if the code you’re using on the client-side will be doing what you expect. Note that our client-side SDK has more classes since it tries to simplify the full API with wrappers
Best Regards,
Andrew Yip
Software Developer
PDFTron Systems, Inc.