Product: StructuredOutputModules, Java (Linux test)
Product Version: 10.6.0
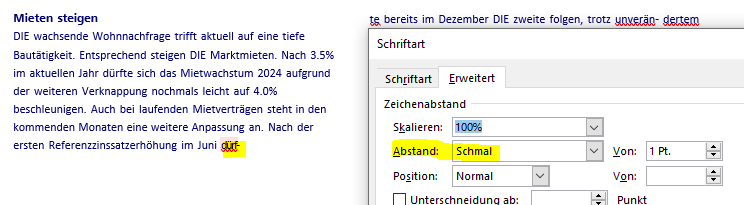
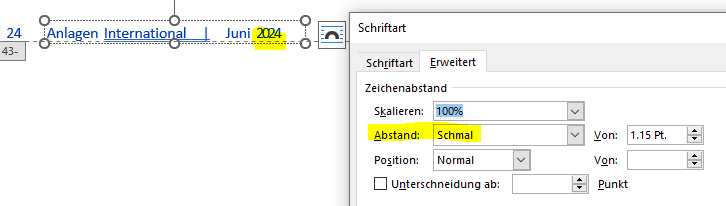
After successfully converting PDF to WORD the WORD output shows font condensed instead of normal.
If this happens we found the condensed part is the most right hand last word, e .g. header or column1 or column2 (see yellow section).
We use Convert.toWord(new PDFDoc(inpBytes), outFile) without any WordOutputOptions.
Any hint is welcome to resolve the issue before going live (this will happen very soon).
Regards Wilhelm Huber
Hi Wilhelm,
To investigate further could you please provide the following information.
- Input file(s)
- Generated output file(s)
- Code and settings used to generate (2) from (1)
Hello
Thank you for any support including hints
AI Juni 2024_895462be-fe06-4927-ad6f-3cc369a203f6.pdf (1.1 MB)
AI Juni 2024_895462be-fe06-4927-ad6f-3cc369a203f6.docx (980.9 KB)
- uploaded
- uploaded
- Convert.toWord(new PDFDoc(inpBytes), outFile) without any WordOutputOptions.
StructuredOutput_Log.log (83.3 KB)
Hello Apryse team members
We need a solution for the production issue (my PO/PM are expecting progress).
Anything which prevents a progress this week?
Regards Wilhelm Huber
Hello Apryse team members
Is anything outstanding in order to get a hint/fix for our production problem?
Please keep me posted asap.
Sincerly Wilhelm Huber